
This article was co-authored by Florian Seidel (AWS).
Amazon S3 Vectors represent a paradigm shift in how we build vector search applications. By eliminating infrastructure management overhead, it enables developers to focus on creating intelligent experiences rather than maintaining complex vector search infrastructure. S3 Vectors delivers high-throughput, low-latency vector operations at scale with automatic scaling, built-in security, and pay-per-use pricing.
In this blog post, we explore an advanced search technique for S3 Vectors that extends its capabilities through iterative result set refinement. The technique is simple to implement and tailored to the unique algorithmic challenges in a distributed environment.
When Iterative Search Becomes Essential
Dynamic result set expansion represents a core pattern in modern vector search applications where the search process adapts based on intermediate results or user feedback. For example, an e-commerce recommendation system might retrieve a broad set of similar products, then filter through a re-ranker model. If too few results remain after filtering, the system automatically expands the search to maintain a target result set size. Interactive applications where users iteratively refine their search scope based on initial findings is another example. These include research tools, content discovery platforms, or exploratory data analysis systems, which allow users to start with a focused query and progressively broaden their investigation, requiring the system to dynamically retrieve additional relevant vectors.
Another important use-case for this algorithm is to retrieve result sets that are larger than supported with a single k-NN search. S3 Vector store, for example, currently supports result sets of at most N vectors. While this is sufficient for most applications, some require more.
Design Challenges for Iterative Search with S3 Vector Store
Implementing iterative search algorithms for S3 Vector store presents unique technical challenges that differ significantly from traditional in-memory vector search systems. Unlike local vector libraries where individual k-NN queries have minimal overhead, in a distributed setting each k-NN query has a substantial cost:
- Network and serialization overhead: Each API call involves HTTP request/response cycles, JSON serialization of high-dimensional vectors, authentication, and network latency. This overhead can easily dominate query time for simple searches.
- Economic efficiency: S3 Vector store charges per API call, making query efficiency directly tied to operational costs. Naive iterative approaches that create numerous, mostly overlapping result sets can quickly become cost-prohibitive and increase latency.
- Result quality requirements: Applications need results that closely approximate what a non-iterative exhaustive search would return.
These constraints eliminate many classical iterative search algorithms that assume low-cost individual k-NN operations. Traditional approaches like iterative closest point methods or random walk strategies often make hundreds of small queries, making them poorly suited for high-overhead distributed systems. The solution requires a fundamentally different approach: an algorithm that maximizes information gain per API call by minimizing result overlap between iterations, and maintains high recall rates with as few queries as possible. This leads us to our iterative search strategy with geometric diversity optimization.
Introducing Iterative Vector Search
To address these requirements, we developed a hierarchical search algorithm that iteratively expands the search space while maintaining efficiency. The approach uses a max-volume selection strategy to choose diverse search vectors for subsequent iterations, preventing search drift and ensuring comprehensive coverage of the vector space.
Algorithm Overview
The hierarchical search process works as follows:
- Initial query: Start with the user’s query vector and retrieve the top 30 most similar vectors
- Diversity selection: Use a greedy max-volume algorithm to select up to 20 diverse vectors from current results
- Parallel expansion: Query S3 Vectors in parallel using each selected vector as a search center
- Result aggregation: Combine new results with existing ones, removing duplicates
- Iteration: Repeat until the desired number of vectors is found or maximum iterations reached
Max-Volume Selection Strategy
The core innovation lies in the vector selection strategy for subsequent iterations. Rather than simply using the closest vectors (which could lead to search clustering), we employ a greedy algorithm that maximizes the hypervolume spanned by the selected vectors:
import numpy as np
def greedy_max_volume(self, start_vector: list[float], results: list[QueryResult], n: int) -> list[list[float]]:
vectors = np.append([start_vector], [r.vector for r in results], axis=0)
selected_idx = [0]
remaining = list(range(1, len(vectors)))
for _ in range(n - 1):
if len(remaining) == 0:
break
best_volume = -1
best_idx = -1
# Test each remaining vector
for i, remaining_idx in enumerate(remaining):
candidate_idx = selected_idx + [remaining_idx]
candidate_vecs = vectors[candidate_idx]
# Compute Gram matrix (dot products between all pairs)
gram_matrix = np.dot(candidate_vecs, candidate_vecs.T)
# Compute determinant of Gram matrix (squared volume)
try:
volume = np.abs(np.linalg.det(gram_matrix))
if volume > best_volume:
best_volume = volume
best_idx = i
except np.linalg.LinAlgError:
continue
if best_idx == -1:
break
selected_idx.append(remaining[best_idx])
remaining.pop(best_idx)
return [results[idx - 1].vector for idx in selected_idx]
This approach ensures that selected vectors are geometrically diverse, leading to better coverage of the embedding space and higher recall rates.
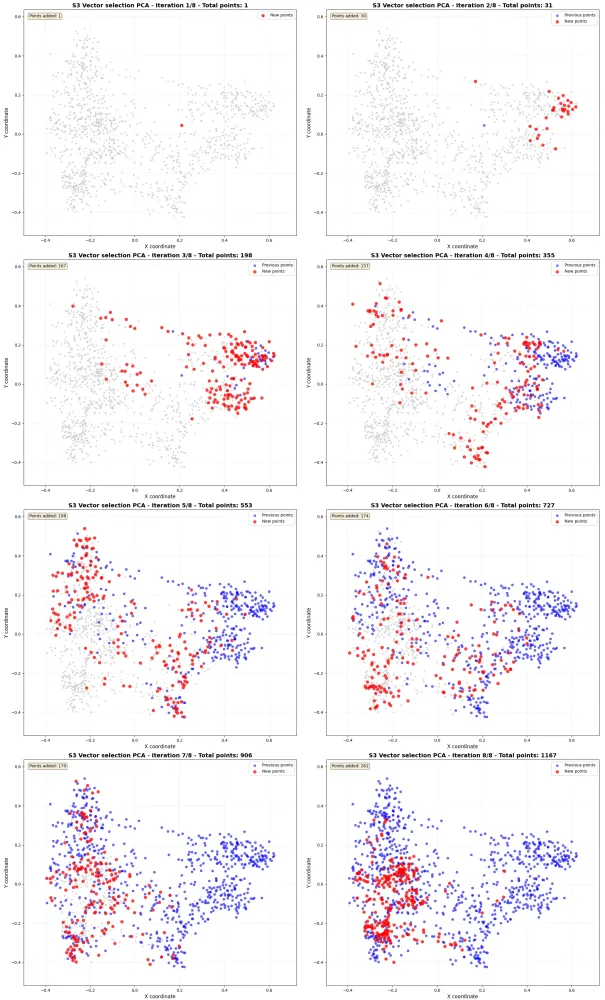
Search Visualization
The visualization below shows the iterative search process, demonstrating how the algorithm progressively discovers vectors from a start vector across the embedding space. The visualization uses principal components analysis (PCA) for dimensionality reduction from 1024 to 2 dimensions:
Implementation Architecture
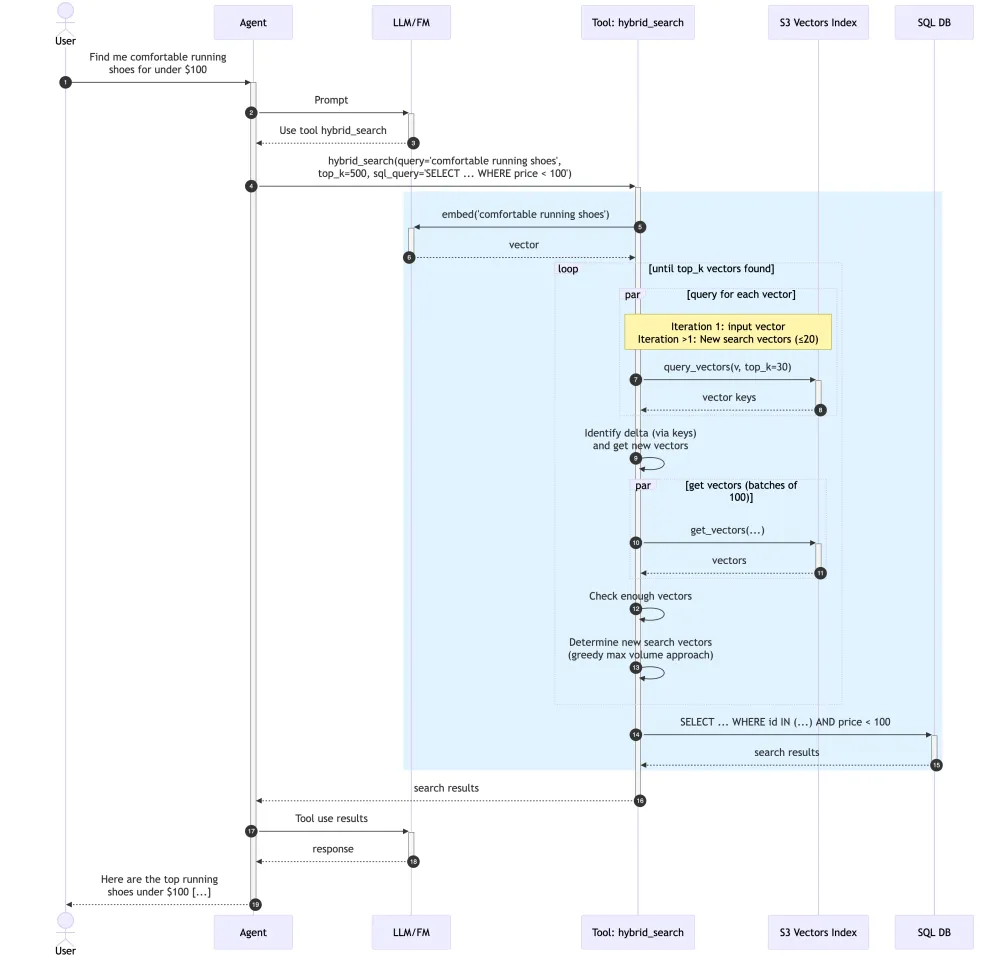
The following diagram illustrates the end-to-end flow using an e-commerce shopping assistant as an example. A user asks for comfortable running shoes under $100. The agent delegates to a hybrid_search tool, which embeds the query, iteratively expands the result set using S3 Vectors with the max-volume strategy, then filters through Athena on structured attributes like price. The final ranked results are returned to the user.
Key Implementation Details
- Parallel processing: The algorithm uses
ThreadPoolExecutorto query multiple vectors concurrently, significantly reducing overall query time. - Early termination: The search stops when the target number of vectors is reached, avoiding unnecessary API calls.
- Configurable parameters:
MAX_ITERATIONS: Maximum number of search iterations (default: 20)SEED_VECTORS: Number of diverse vectors selected per iteration (default: 20)top_k: Target number of results to retrieve
def query(self, query_vector: list[float], top_k: int = 100) -> list[QueryResult]:
results: set[QueryResult] = set()
iterations = 0
next_search_vectors = [query_vector]
with ThreadPoolExecutor(max_workers=self.SEED_VECTORS) as executor:
while iterations < self.MAX_ITERATIONS:
iterations += 1
# Query vectors in parallel
new_vectors = executor.map(
partial(self.query_by_vector, top_k=30),
next_search_vectors,
)
delta = set(itertools.chain(*new_vectors)).difference(results)
# Early termination if we have enough results
if len(results) + len(delta) >= top_k:
results.update(delta)
break
# Fetch vector data for new results
delta_vectors = self.get_vectors_for_keys(
executor, list(map(attrgetter("key"), delta))
)
for d, v in zip(delta, delta_vectors):
d.vector = v
results.update(delta)
# Select diverse vectors for next iteration
next_search_vectors = self.greedy_max_volume(
query_vector, list(results), self.SEED_VECTORS
)
return sorted(results, key=lambda x: x.distance)[:top_k]
Performance Evaluation
We evaluated the hierarchical search algorithm against standard approaches using a dataset of 21,630 AWS documentation embeddings (1024 dimensions, Titan embeddings).
Experimental Results
The max-volume hierarchical search achieved significant improvements in recall performance:
| Algorithm | Recall | Precision | Avg Searches | Distance Ratio |
|---|---|---|---|---|
| Max-Volume Hierarchical | 68.90% | 68.90% | 11.7 | 1.03 |
| Approx | 57.50% | 57.50% | 11.7 | 1.08 |
| Normal | 51.60% | 51.60% | 5.2 | 1.13 |
| FAISS Approx | 21.70% | 22.90% | 1 | 1.14 |
Performance by Result Size
K=50 Results:
- Max-Volume: 78.8% ± 8.4% recall (5.0 searches)
- Exhaust: 71.2% ± 6.0% recall (5.0 searches)
- Normal: 67.2% ± 4.1% recall (2.2 searches)
- FAISS: 23.3% ± 1.6% recall (1.0 search)
K=100 Results:
- Max-Volume: 72.0% ± 9.5% recall (10.0 searches)
- Exhaust: 56.2% ± 10.7% recall (10.0 searches)
- Normal: 49.0% ± 9.1% recall (4.4 searches)
- FAISS: 22.7% ± 2.4% recall (1.0 search)
K=200 Results:
- Max-Volume: 55.8% ± 3.9% recall (20.0 searches)
- Exhaust: 45.1% ± 8.7% recall (20.0 searches)
- Normal: 38.5% ± 9.6% recall (9.0 searches)
- FAISS: 19.0% ± 2.0% recall (1.0 search)
Query Latency
Typical execution times range from 1–2 seconds per iteration, with the total query time scaling linearly with the number of iterations required. The parallel processing approach ensures that each iteration is efficiently batched with parallel S3 Vectors API calls.
Best Practices and Recommendations
When to Use Hierarchical Search
Consider implementing hierarchical search for applications that:
- Require high recall rates (>50% of truly relevant vectors)
- Can tolerate slightly higher query latency (2–10 seconds)
- Need comprehensive coverage for downstream processing
- Implement multi-stage ranking or filtering pipelines
Configuration Guidelines
For high recall applications:
- Set
SEED_VECTORSto 20 for optimal diversity - Use
MAX_ITERATIONSof 15–20 for comprehensive coverage - Target
top_kvalues of 100–500 for best efficiency
For latency-sensitive applications:
- Reduce
SEED_VECTORSto 10–15 - Limit
MAX_ITERATIONSto 5–10 - Use smaller
top_kvalues (50–100)
Cost Considerations
The hierarchical approach requires multiple S3 Vectors API calls, which impacts cost:
- Standard query: 1 API call
- Hierarchical search: 5–20 API calls (depending on configuration)
- Cost increase: 5–20x for significantly improved recall
Monitor your usage patterns and adjust parameters based on your recall requirements and budget constraints.
Integration with Existing Workflows
The hierarchical search algorithm integrates seamlessly with existing S3 Vectors implementations. The S3VectorsIndexManager class provides a drop-in replacement for standard query operations:
# Standard S3 Vectors query
s3vectors_client = boto3.client("s3vectors")
results = s3vectors_client.query_vectors(
vectorBucketName=bucket_name,
indexName=index_name,
queryVector={"float32": query_vector},
topK=30
)
# Hierarchical search with same interface
manager = S3VectorsIndexManager(config=config, embeddings_client=embeddings_client)
results = manager.query(query_text, top_k=200)
Conclusion
The hierarchical search algorithm provides a practical solution for applications requiring comprehensive vector retrieval from Amazon S3 Vectors. By leveraging geometric diversity in vector selection and parallel processing, the approach achieves significantly higher recall rates while maintaining reasonable query performance.
This technique demonstrates how thoughtful algorithm design can work within service constraints to unlock new capabilities. As vector search becomes increasingly central to AI applications, such optimization strategies will be essential for building robust, scalable systems.
The hierarchical search approach is particularly valuable for research workflows, comprehensive analysis tasks, and applications where missing relevant results has significant business impact. By understanding both the capabilities and constraints of managed services like S3 Vectors, developers can build more effective solutions that balance performance, cost, and functionality.
☁️ Amazon S3 Vectors: Documentation
📖 Machine Learning on AWS: Resources